

how to become a data scientist
How to Become a Data Scientist
With courses, books, and movies almost everything available for free
Many people have asked me in recent months how they can become a data scientist, and after learning most people's main questions and improving my answers over time, I have decided to spend a great deal of time making this guide so that most people have access to it.
Index
1- What is a Data Scientist?
2- What is the required Background?
3- What to study?
4- Step by step of the subjects.
5- Recommendation of Courses, Books and Movies.
6- Next steps.
1. What is a Data Scientist?
If you do know wh a t a Data Scientist is, you are rare to find, as since even the most experienced professionals still have difficulty defining the scope of the area. One possible delimitation is that the data scientist is the person responsible for producing predictive and / or explanatory models using machine learning and statistics. A more complete (or detailed) description can be found in the following link:
To be a data scientist is to be always studying, updating and learning. Learning to apply Machine Learning will not make you one, change is not just a collection of techniques but a change of mindsight to face problems, it is thinking skeptically, without prejudice and it will not come quickly.
This introductory guide is a way to save your time looking for the best material or order of learning, not replacing the hundreds of hours required for your training.
2. What is the necessary background?
The first waves of data scientists were primarily from development personnel, computer scientists, and engineers. They were the ones who created machine learning models, that optimized the process and minimizedthe cost function. They would analyze unstructured data, create specific programs for each problem, and, due to limitations of the computational processing, do manual map / reduces. Fortunately that time is gone, most of these operations have been greatly facilitated by high-performance programs and packages, and currently most Data Scientist is spending more time on modeling and less on engineering.
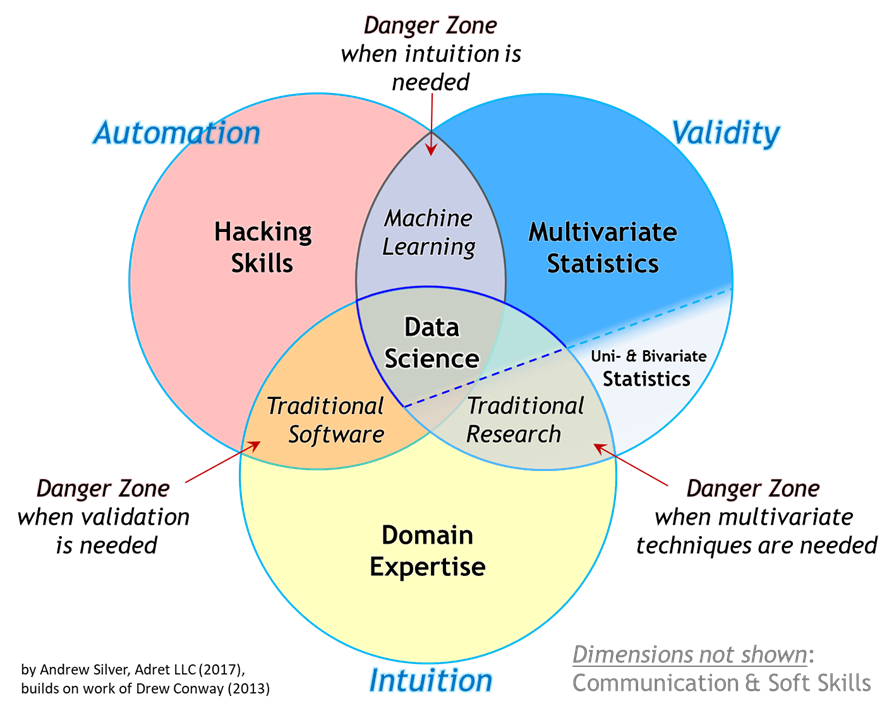
The good news is, today, this learning curve is not that steep anymore. People from different backgrounds have to opportunity to join this field and one of the main reasons is the intense use of Python which is a high- level language acting as an API for much more performative low- level languages. In other words, you don't have to waste energy worrying about complicated syntax, because, writing in Python is like writing in English. You just need to study for In a few weeks to master the basics. Besides that, most of the data scientist's time-consuming stack is being automated or specialized in other areas such as the Machine Learning Engineer and the Data Engineer. Therefore, leaving the part of science for the scientist.
Working with Big Data today has become as simple as writing SQL in environments such as DataBricks.
Making algorithms in production highly scalable and available is becoming simpler with tools like SageMaker and its competitors.
Even the creation of complex feature engineering is being automated with AutoML.
In a nutshell, today a programming background is still important, but the importance is decreasing, and what I expect for the future is that programming will cease to be the core and it will become an exclusive activity for IT professionals. Therefore, I would like to give you one advice: focus your time and energy on analysis, modeling and science.
3. So what to study?
Programming: Python & SQL
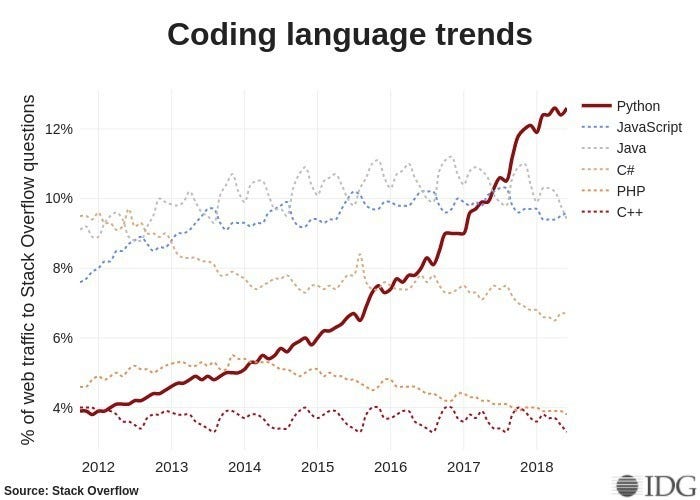
You definitely need to learn how to program, and many languages meet that demand, whether it's the most performative like Scala, or the more academic and statistical like R, or the general-purpose like Python, the latter is the most obvious decision for anyone starting out and doing. The reason is simple. Python has the largest community for data analysis, it will be much easier to find examples of analyzes in Kaggle (Machine Learning Competition Website Becoming a Portfolio for the Data Scientist), find code examples in the Stackoverflow (Q&A site with most beginner and often advanced questions as well) and job openings as it is the most popular language on the market.
Machine Learning: Denominator in Common.
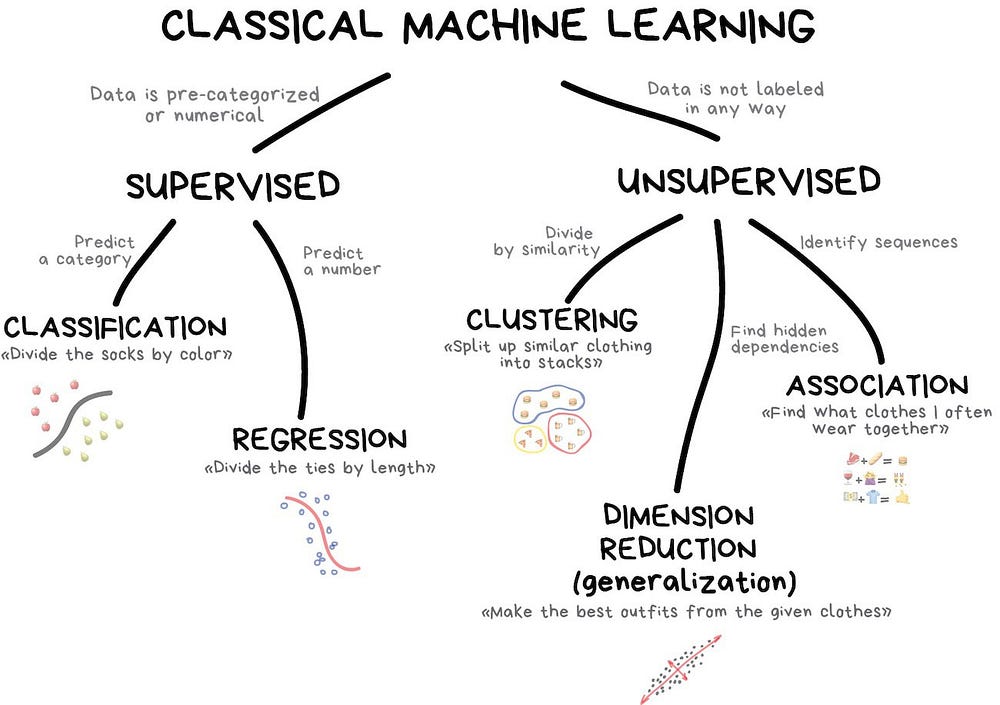
No way to run, you inevitably have to go through the basics of Machine Learning. When I first started studying Machine Learning in 2014, most of the courses focused on deriving the models, much like expected from a formal degree, and a lot of DS was trained that way,
This gives you a tremendous ability to understand how different models work inside and even think about the best model for each problem. My recommendation is that you do not do this. The cost benefit of studying a number of different model classes is very small, you need to know (per hour) that a model is a BlackBox who can turn inputs (our variables such as the person's height, where they live and how much they earn) into an output (such as their likelihood of being a fraudster). There are many techniques that are common to almost every model and my suggestion is that you learn these techniques first and only then focus on understanding the their mathematical difference and implementation details.
Statistics: Basic well done.
I have left the best, the most important and (unfortunately) the hardest in the end. It is this skill that will differentiate is a Data Scientist from a Machine Learning Engineer. There are not many shortcuts here. You should start with descriptive statistics, know how to do a good exploratory data analysis (EDA), or at least the basics of probability and inference, understand well the concepts of selection bias, Simpson Paradox, association of variables (in particular variance decomposition methods), the basics of statistical inference (and the famous, A / B testing as inference is known in the market), and a good idea for experiment design.
4. What is the ideal track?
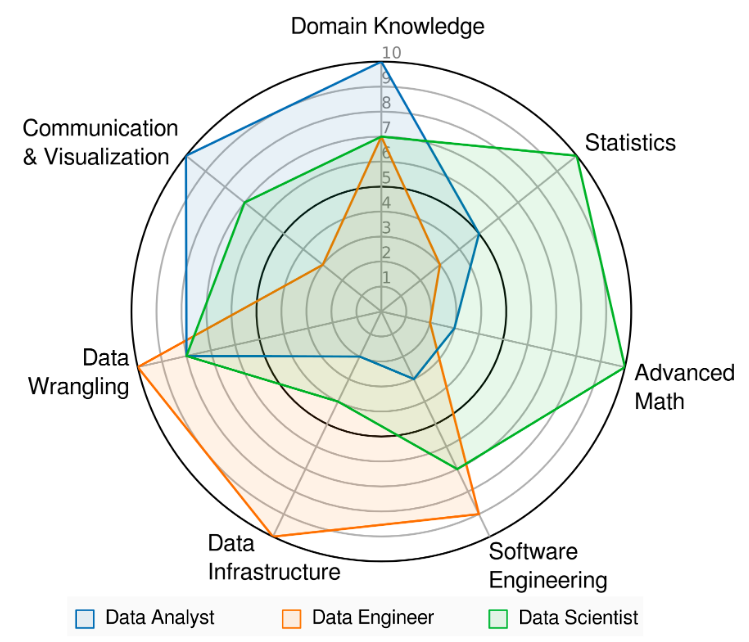
This is a difficult question and may have different answers according to each person's background. But in case you are a beginner, I would suggest, and as you advance, you should follow the sub-area that you like most.
Prerequisites:
- Math:Algebra -> Calculus.
- Statistics: Descriptive Statistics -> Probability> Inference
- Python: Data Types -> Iterations -> Conditionals -> Functions
Basic:
I call basic the knowledge that should be common to any Data Scientist, regardless of background or specialty.
- Data analysis with Pandas (open different files and manipulate them)
- Statistics: Association between variables, analysis of variance, hypothesis testing;
- Viz: matplotlib; seaborn; bokeh;
- Data: SQL, Querying APIs;
- Supervised Machine Learning: Gradient Descending -> trade-off between bias and variance -> validation -> regularization -
> regression and classification metrics -> balancing -> parameterization -> feature selection; -> Idea of Ensembles; - Unsupervised Machine Learning: Clustering, Dimensionality Reduction
Intermediary:
At this point a data scientist should specializes in a smaller (and more difficult) areas;, in this stage there are hardly people who are experts in all areas, but I will show you each area:
- Statistics: Bayesian Statistics, Causal Experiments; Econometrics (if experiment is not possible), Data Munging;
- Data: Data Ingestion, Web Scrapping, Unstructured Data, Big Data Environments;
- Production Algorithms: Transformation Pipeline; Containers and Creating APIs;
- Creating multi-layer models (stacking) and meta-models,
Embeddings models; Interpreting models with LIME and SHAP; - Machine Learning with Self-Correlated Data (or Dashboard data);
Advanced:
I have selected the following topics as Advanced not due to its difficult but because they are the most specialized knowledge. It is perfectly acceptable for an experienced data scientist to never have to use part of these skills simply because he or she has not had an opportunity in his or her job. But again,
It is interesting to know the basics of all skills.
Deep Learning: Deep Reinforcement Learning, Natural Language Processing, Computer Vision;
Statistics: MCMC, Causal Modeling with Propensing Score Matching and Instrumental Variables, Synthetic Counterfactuals.
Data: Graph-oriented data, data lake, streaming data, Low latency APIs, kubernetes
5. Where to learn all this?
Since I have written this guide to anyone who is interested in Data Science, living in any part of the world, I will only recommend online courses, preferably free ones. All of them at least in English subtitles that cover the basic part of the trail mentioned above.
Python:
The most complete recommended Python courses are the Introduction to Computer Science and Programming Using Python by MITx (>120h) or the Python for Everybody by Michigan (>30h) you can choose according to how much time you have available. Both courses have already formed thousands of people starting from scratch, so you have no prerequisites and you will be writing small programs.
In case you are already comfortable with some other programming language but don't know Python, you can choose the 4-hour short course from DataCamp (free).
Machine Learning:
A legion of DS learned from Andrew NG in his famous course ofMachine Learning by Standford. I can't not recommend it. He takes a more technical approach and uses Octave language (a kind of open source Matlab). The course is ~ 60h and the prerequisites are linear algebra and basic statistics.
Other complete options would be:
Machine Learning from the University of Washington, Coursera (> 180h)
Nanodegree de Machine Learning by Udacity (not free) (>120h)
Stats
(longer and fuller) Fundamentals of Statistics, MIT, free, > 160h. This is a very broad course, itcan be too technical if you do not have a background in math or related area as it is a course that derives the math behind the concepts. This course will teach you:
- How appropriate is a particular model for a specific data set?
- How to select variables in linear regression?
- How to model nonlinear phenomena?
- How to view large data?
If you want to start with shorter (and basic) courses, here are the alternative options:
Probability by Harvard, edX, free ~ 12h. This is a more pragmatic introductory course than the previous one, focusing on the themes of probability, you will learn several fundamentals such as:
- Random variables,
- independence,
- Monte Carlo simulations,
- expected values,
- standard errors,
- Central Limit Theorem.
Inference and Modelling, Harvard, edX, free ~ 12h. Another important theme that complements the previous practicability course is the Inference course also by the Harvard team. In this course you will learn the substratum needed to make good statistical modeling, margin of error, and understand how reliable the predictions are The samples from this course were, all with real world examples like data from the 2016 election.
Book Recommendation
Introductory:

Data Science From Scratch by Joel Grus This is an excellent book if you are absolutely beginner, it is a reading that does not assume you have prior knowledge and can be a great way to learn the basics of statistics and python while understanding the construction of algorithms. I do not recommend it to anyone who already has a base because it can be too slow. Recently released the second version of this book.

Python for Data Analysis: Data Wrangling With Pandas, NumPy and IPython by Wes McKinney. All the books here are clearly great readings, but here is a case of reading that is a great compilation of simple (or not so simple) techniques that will save you a lot of time.
It's not a statistical book or a machine learning book, but you'll need to go through these techniques to do anything minimally close to the real world.

Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Here is an excellent and up-to-date book (I even recommend the recently released second version of this book already updated to excellent tensorflow 2.0). The first part talks about the "common denominator" of machine learning algorithms and the second part focuses on neural networks.
Besides that, has a great github repository with all the book's code. Available here-v2 ou here-v1.

Statistics in Plain English. Light and uncomplicated reading for those who do not have a background in statistics. Each chapter describes a different statistical technique, ranging from basic concepts such as central tendency and description of distributions to more advanced concepts such as tests, regression, repeated measures ANOVA, and factor analysis.
Each chapter begins with a brief description of the statistic and when it should be used followed by further reading which may be optional.

Think Stats: Probability and Statistics for Programmers available for free by clicking on the link. In this delightful reading you will drop the heavy formulas and embark on the analysis of actual data from national health institutes. For those who need something more practical than theoretical to learn or if they already know the theory well and want to see how to apply it in the real world. . Superficial and interesting book.

An Introduction to Statistical Learning A classic, full of examples and applications (in the R language). Indispensable! Topics covered include linear regression, classification, resampling methods, retraction approaches, tree-based methods, support vector machines, clustering, and more.
Color charts and real-world examples are used to illustrate the methods presented.
Not so introductory..

Elements of Statistical Learning (free available at link) This post is a milestone in the Area. Before it different areas developed their own languages and symbols to use statistical concepts and the author gathered all this under the shadow of statistics. Here the emphasis is on concepts rather than mathematics.
Many examples are given with the help of good color graphics. It is a valuable resource for statisticians and anyone interested in data mining in science or industry. It approaches different algorithms and techniques of Machine Learning with statistical uses.
.
.

Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville, Elon musk said just that about the book: "Written by three experts in the field, Deep Learning is the only comprehensive book on the subject." The first part of the book is a fairly thorough introduction to more traditional Machine Learning while focusing on the rest. of the book is on Deep Learning and the frontier of knowledge.
Available online for free.

Fluent Python: Clear, Concise, and Effective Programming A really complete book (I don't know anything more complete than this reading) for you to learn even the smallest details of Python. Advanced material, not recommended for those who started with Python now.
.
.
.
.
.
.
.
Bayesian Methods for Hackers By: Cam Davidson-Pilon. Reading that helps give some pragmatism to this area of super important but reasonably poor content compared to frequentist statistics. Lightweight text that focuses primarily on concepts and applications and leaves math in the background,
finally can combine probalistic programming with Bayesian statistics in an excellent book.
.
.
.
Recommendation of Movies and Documentaries.

MoneyBall, 2011 It's the kind of movie that makes us passionate about data analysis. He tells the story of Billy Beane who catches a reasonably small baseball team and through data analysis, a lot of courage and a bit of politics can leave the old feeling methods behind and revolutionize a super traditional sport. IMDB Note 7.6. unmissable
. (a reference is that grade 8 is in the top 250 of the movies history)

The AlphaGo documentary 2017 is another shining example of how to turn complex machine learning algorithms into a documentary intelligible to all audiences. Available on Netflix, you'll learn part of Machine Learning's incredible potential in a game that was considered intrinsically human a few years ago. Note 7.9.
The Joy of Stats, 2010 is an apology for the use of statistics, presented by the excited professor Hans Rosling, he shows with various visual tricks how different areas are dealing with this new era of data flooding. IMDB Note 7.3 (great!)
The Age of Big Data, 2013bbc quee documentary explores three very interesting cases:
- Los Angeles Police Officers Getting a Prediction of Where Crime Is Most Likely to Occur in the Next 12 Hours
- London City scientist turned trader believes he has found secrets to make millions with math
- South African astronomer who wants to catalog the sky by listening to all the stars.
Recommended places to stay up to date..
KAGGLE. The first recommendation is not exactly to keep up to date, but it is a rather rich source of examples and discussions, it is the Kaggle Site purchased by Google. There are competitions there (including high cash prizes), courses, plenty of notebooks, discussions and recently it's becoming a kind of data scientist curriculum.
So if you want to become one, it's worth knowing.
KDnuggets . Don't let this 90s site look fool you, but it really was created in 1997 and since then has been gathering a lot of quality posts and content, mostly with tips and applications.
AnalyticsVidhya. & TDS These are blogs with communities of hundreds of thousands of data scientists of all levels sharing content. It takes a little experience here to separate the chaff from the wheat but there is a lot of quality.
Montreal.ai One of my favorite hubs, they post on different social networks and if you follow your channel will be constantly updated with the frontier of knowledge. High quality content is difficult to keep up with the pace of innovation in the area.
6. Next Steps:
Obviously there are many steps to be taken later. But each person will end up specializing in some subarea that will interest you most, such as:
Bayesian Statistics, University of California.
Econometric s (Causal Inference) Erasmus University Rotterdam
Deep Learning by deeplearning.ai
Computer Vision by deeplearning.ai
Natural Language Processing by Higher School of Economics or NLP in TensorFlow
Reinforcement Learning by University of Alberta
If you liked this post you may also like the following:
- What is the scope of data science;
- Interpreting Machine Learning;
- A Brief History of Statistics;
how to become a data scientist
Source: https://towardsdatascience.com/how-to-become-a-data-scientist-2a02ed565336
Posted by: singhsourn1974.blogspot.com
0 Response to "how to become a data scientist"
Post a Comment